Digital-twin simulation
One of the highlights of my contribution to the Muon Collider project is the optimisation of the digital-twin simulation process, which has led to the throughput increase by at least x100.
Out of all the things I've worked on, I chose to write about this specific aspect because it demonstrates the importance of looking at the big picture through a critical lens, and can be appreciated without going too deep into the technical details. I think it also emphasises the science element in the term data-science, in contrast to what the corporate world focuses on most of the time, which is primarily data.
Muon Collider context
Muon Collider is a hypothetical future flagship experiment that is considered as a possible successor of the Large Hadron Collider – the largest and most powerful human-made particle accelerator in the world today. Its overall purpose remains the same – push further the frontier of fundamental research in high-energy physics by studying collisions of particles at much higher energies than has been possible until now.
The conceptual novelty of the Muon Collider is that instead of colliding stable particles used in all previous experiments, like electrons, protons or heavy ions, the Muon Collider would collide muons. Muon is a fundamentally unstable particle that only lives for 2.2 us (microseconds) at rest before it decays into stable particles – an electron and a neutrino. This is a huge technical complication, as it requires those muons to be created, accelerated and collided in a very short time before they decay, whereas experiments like those at the LHC can keep circulating the same beam of protons for days.
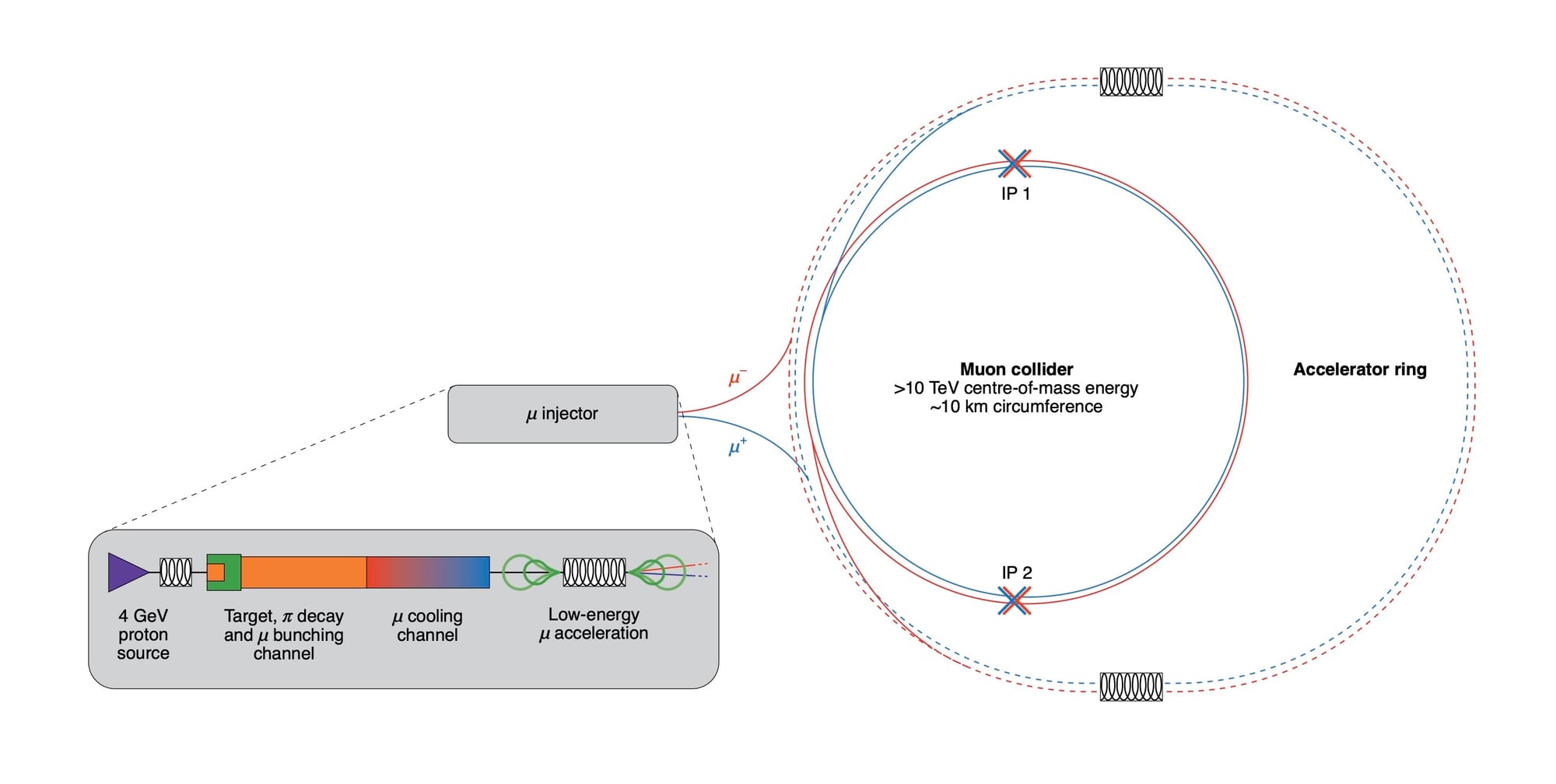

The reason such a challenging concept is even considered is that it also provides some unique advantages that no other kind of accelerator can offer. As of today, it is the only way to provide extremely-high-energy collisions in a compact form-factor at a low running cost. Any other kind of accelerator would have to compromise on at least one of those aspects.
› More on the unique advantages
In a high-energy collider experiment we normally want to achieve three things:
- collide particles head-on at the highest possible speed – to have more energy going into the creation of new, possibly unknown, particles;
- transfer the most of particle's energy into the actual collision – to keep the amount of wasted energy to the minimum;
- collide particles as frequently as possible – to collect more data, which enables higher-precision statistical analysis.
Up to now there have been two major choices of particles to be used in collisions:
- electrons or positrons – point-like particles without known inner structure, bringing their whole energy into the collision;
- hadrons or ions – complex structures made of smaller point-like particles – quarks and gluons, resulting in only a tiny portion of their energy going into the collision between those individual point-like constituents.
Another complication comes from the phenomenon called synchrotron radiation – a charged particle moving in a circular trajectory will lose more energy the faster it goes and the lighter it is. This limits the speed to which lightweight particles like electrons can be accelerated in a ring, after which most of the energy will be wasted through this radiation. Heavier particles, like hadrons, can be accelerated to much higher speeds in a ring, but most of the time only a small portion of their energy will go into the collision.
Instead, muons combine the best of the two worlds – they are point-like particles, like electrons, but they are x200 heavier and therefore lose x10000 less energy through synchrotron radiation. This allows to accelerate them in a ring to extremely high speeds, while bringing all that energy into the actual collision.
Digital twin
Given the extreme complexity and financial cost that projects of this scale have, they rely on sophisticated and highly detailed feasibility studies, that often start 10-20 years before the actual experiment is physically built. Such studies usually involve a dedicated group of researchers and engineers building a digital twin of the future experiment and performing all the relevant tests and analysis on the high-fidelity simulated data.
Muon Collider is no exception, and our group has been working on such simulation studies since 2018. Over the time we've built a software framework for detailed simulation of the experiment to evaluate different detector layouts, sensor technologies, computing algorithms, etc.
All this allows us to come up with the optimal detector designs in terms of performance, cost, longevity, construction complexity and other metrics that ultimately define the feasibility of the whole project. And most importantly, all these decisions can be made with very little effort and money spent on the actual physical prototypes, which would be much slower and more expensive to iterate on than in a digital twin.
Simulation process
Digital-twin simulation of a Muon Collider detector follows the classical approach of any particle-physics experiment. It involves 4 distinct stages that operate at different scales of space and time, usually combined under a common software framework:
- simulate high-energy collisions between the incoming muons, including all the cascading interactions and decays until the formation of stable particles;
- simulate the propagation of stable particles through the physical materials in the detector, recording all the microscopic interactions and energy deposits in the sensors;
- simulate the response of the sensors to those interactions and energy deposits, including all the relevant physical and electronic effects, such as noise, latency, segmentation, cross-talk, sensitivity thresholds, data throughput, etc.
- perform analysis of the simulated data , like it would be in a real experiment, in conjunction with the underlying history of each signal from the previous stages of simulation, evaluating the performance of every element.
Background and pile-up
For the simulation to accurately describe what would happen in the real experiment after stage 4 it is crucial that all the preceding steps get all the relevant inputs. In particular, a real experiment would have to deal with the so-called background – energy deposits in the detector material caused by particles that do not come directly from the primary high-energy collision, but instead come from other processes that we're not interested in but cannot avoid. Therefore, an accurate simulation has to include those background particles in the 1-st stage of the simulation process, which then are propagated all the way to the last stage.


Yellow dots showing the positions of multiple pile-up collisions at the LHC, from which energetic particles originate
Over the many years of LHC operation, starting from 2010, the notion of pile-up became the de-facto standard way to look at the background signals in the detector. It's called pile-up because those background particles come from additional lower-energy collisions of protons happening synchronously with the primary collision. This creates a series of waves of energy deposits effectively piling-up over each other, which are usually registered as one combined signal by the detector.
› The reason behind pile-up
Pile-up is the unavoidable side-effect of the proton-beam structure at the LHC. Given that protons are mostly empty inside, it is very unlikely for the tiny constituents of the two protons to actually hit each other. Therefore the proton beams are shaped into tightly-packed bunches of protons, such that a really hard collision is more likely to happen when the two bunches cross each other.
While this tight packing makes hard proton-proton collisions more frequent, other protons from the same bunches can hit each other as well, but with smaller impact. This effectively creates one hard collision and a certain number of softer collisions along the beam line – all within the same detection area of the experiment.
This number of softer pile-up collisions is what we refer to as pile-up level, which is kept below certain threshold by the LHC operators to protect the detector electronics from saturation.
Muon Collider is different
At the Muon Collider there is no need to have tightly packed bunches of muons, since they are not as empty inside as protons. Therefore, we can easily afford having only one muon-muon collision at a time, without any pile-up. Yet the muons constantly decay inside the beam, and the resulting electrons hitting various elements of the experiment create a huge amount of background particles anyway. We call them Beam Induced Background (BIB) particles.
From the radiation perspective there is not much difference between pile-up at the LHC and BIB at the Muon Collider – both put similar requirements on the radiation hardness of the detector materials and electronics. But there is a conceptual difference in its behavior that has deep implications on the choice of mitigation strategies and simulation approach.
Most prominently, pile-up signals at the LHC come from relatively few particles with high-enough momentum to go through the whole detector in exactly the same way as particles from the primary collision. This aspect lies at the foundation of the pile-up subtraction algorithms that reconstruct those individual particles and trace them back to the points that have a noticeable offset from the primary collision.
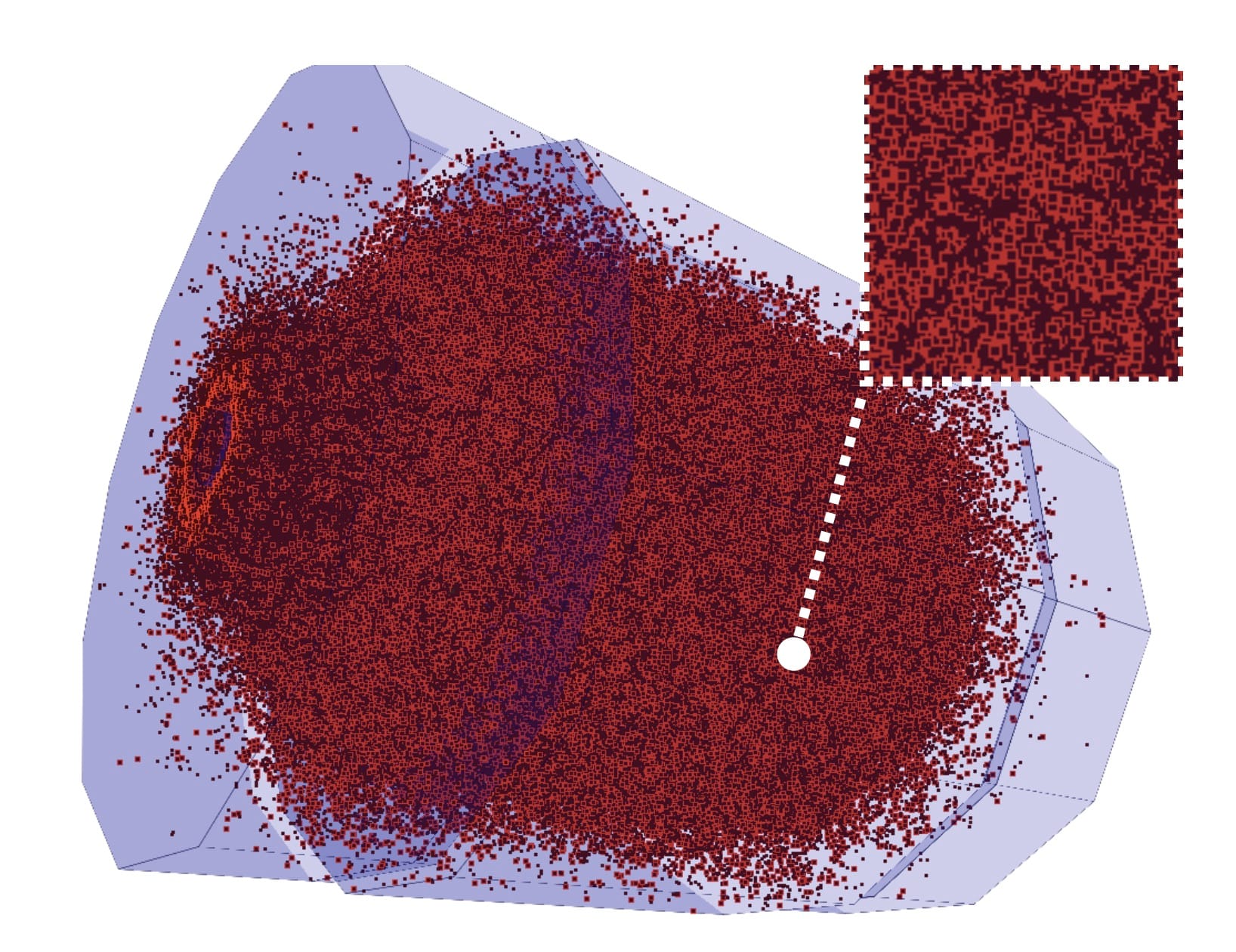
A small fraction of trajectories of low-momentum background particles at the Muon Collider
This is not the case at the Muon Collider, where BIB is made of hundreds of millions of low-momentum particles, illuminating almost uniformly the whole detector. This creates a huge computational problem, especially for the stage 2 of the simulation process – propagation of each particle through the detector material to record individual energy deposits. Simulating the passage of one very energetic particle requires much fewer computations than simulating a thousand of low-momentum particles.
It became apparent quickly that no brute-force software optimisation can make the simulation process comparable in speed to that of the LHC experiments. A different approach was needed and that's what I decided to explore.
Optimisation approach
As explained above, the main source of the problem is the overwhelming number of individual particles that need to be simulated as they propagate through the detector. Every particle also needs to be loaded from disk into memory and then the resulting energy deposits need to be written back to disk. This adds additional book-keeping overhead in terms of I/O latency and storage space, especially on distributed systems used for such simulations. Therefore, reducing the number of input particles in the first place would be the best possible option.
Simply removing particles from the background sample is not acceptable at the LHC, since those particles look almost exactly the same as the signal particles that we're interested in. Therefore, removing any portion of them would introduce a bias in the outcome of the simulation. Instead, in the case of Muon Collider there is a fundamental difference between the signal and background, which in principle could be exploited if we go deeper into the technical details of how the experiment operates.

Time of arrival
The first relevant aspect of the experiment is the time it takes for the background particles to arrive to the detector. Unlike the LHC, where background particles arrive synchronously with the signal, at the Muon Collider they come from the muons decaying at various locations along the beam, taking trajectories of different lengths. As a result, their arrival time in the detector is spread across several milliseconds, in contrast to signal particles that arrive within just few nanoseconds (ns) from the main collision – a million times shorter time window. Besides, the detector itself needs no more than 10 ns to integrate its signal and to do the measurements, being completely unaffected by any particles reaching it later, except for the radiation damage that it will slowly accumulate.
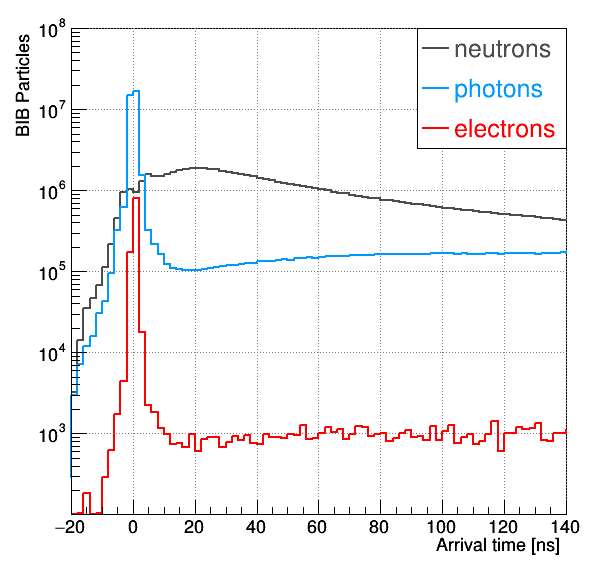
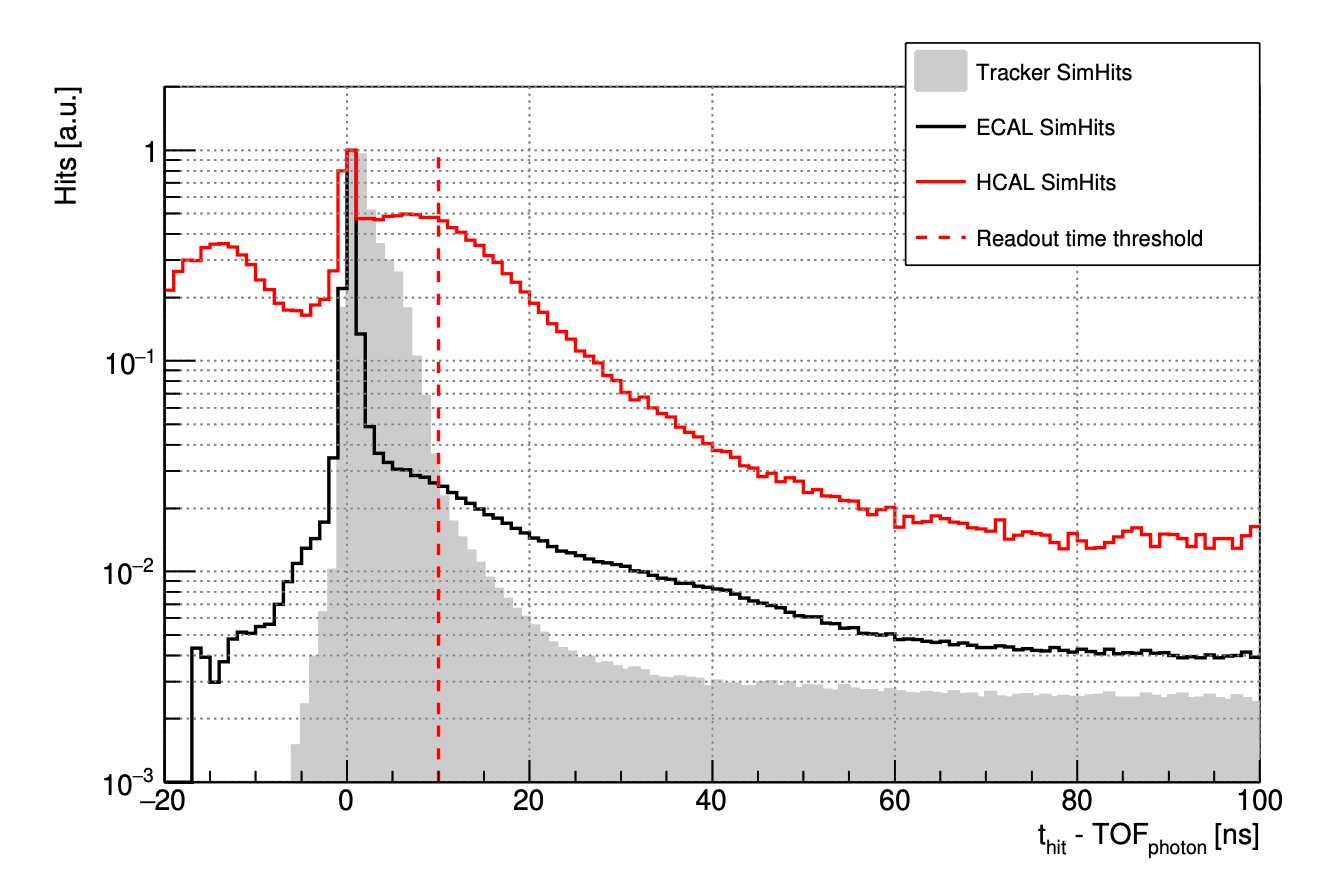
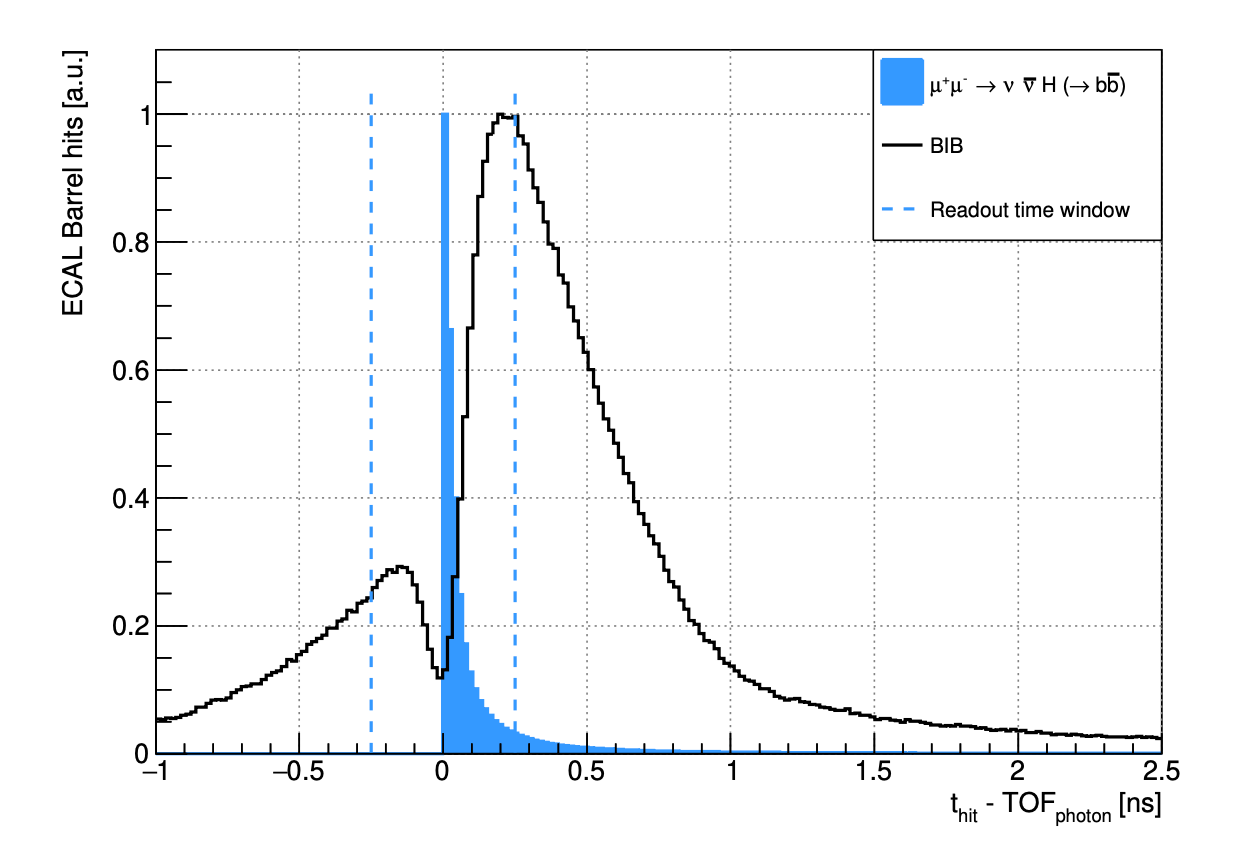
Spread of arrival time of different types of background particles (left) and the corresponding detector signals in different detector subsystems (right)
This means that when the detector is precisely synchronised with the collision of the two muons, we can safely ignore particles entering the detector region at any point after 10 ns. To be safe, we've added an extra margin, expanding the time window to 25 ns. By completely excluding such late particles from the simulation, the processing time of the whole collision has reduced by a factor 6, from 3,040 hours to 480 hours.
Slow neutrons
The majority of the remaining particles are neutrons – heavy neutral hadrons that can scatter around the detector for a long time before they stop, creating a particularly large number of very small energy deposits across the calorimeter section. This makes them more expensive to simulate than other types of particles, like electrons and photons, which are stopped much sooner.
Being so heavy, neutrons travel slower than photons of the same momentum, arriving to the detector significantly later. This opens an additional possibility for discarding particles that are irrelevant for the simulation outcome.
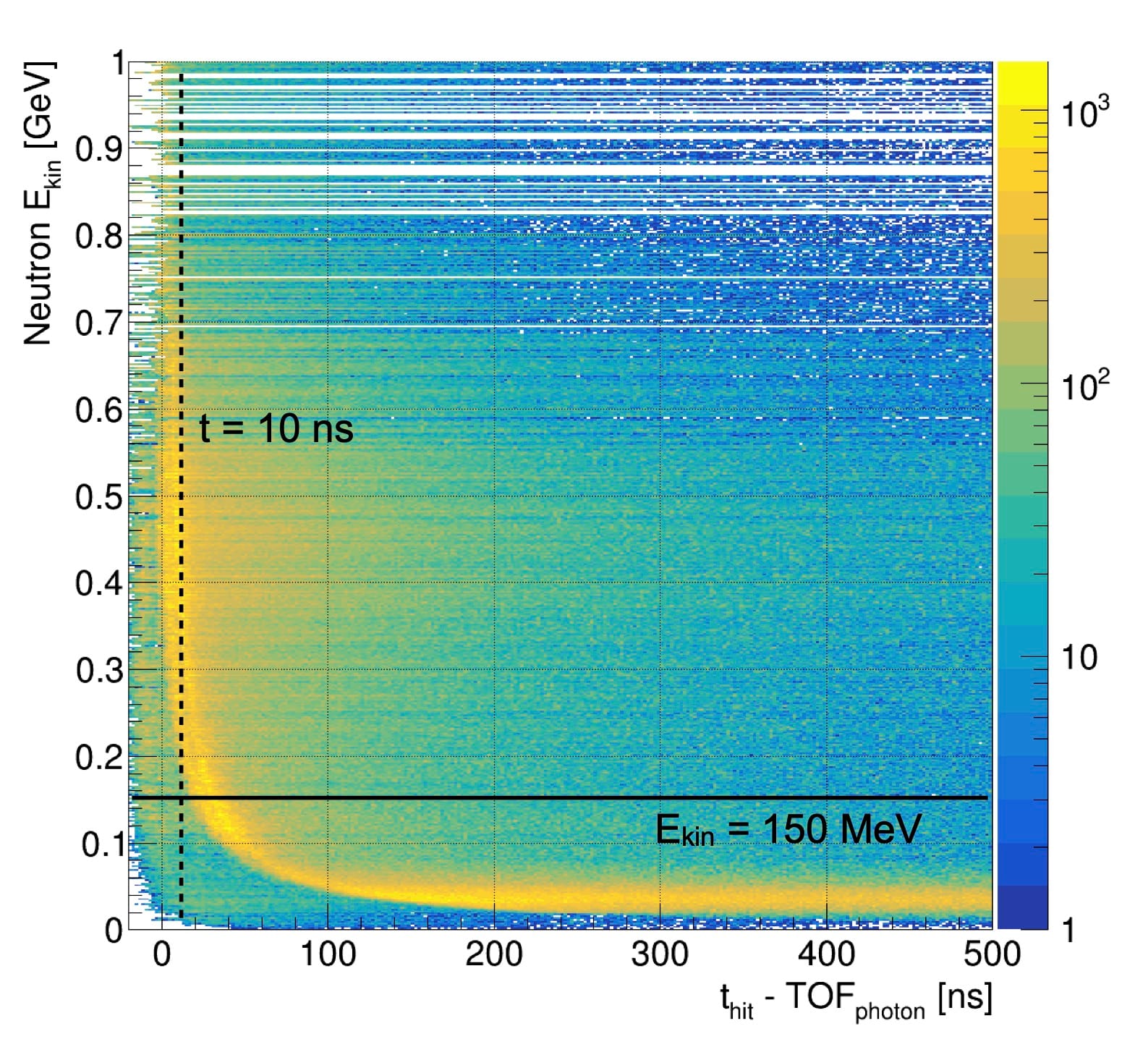
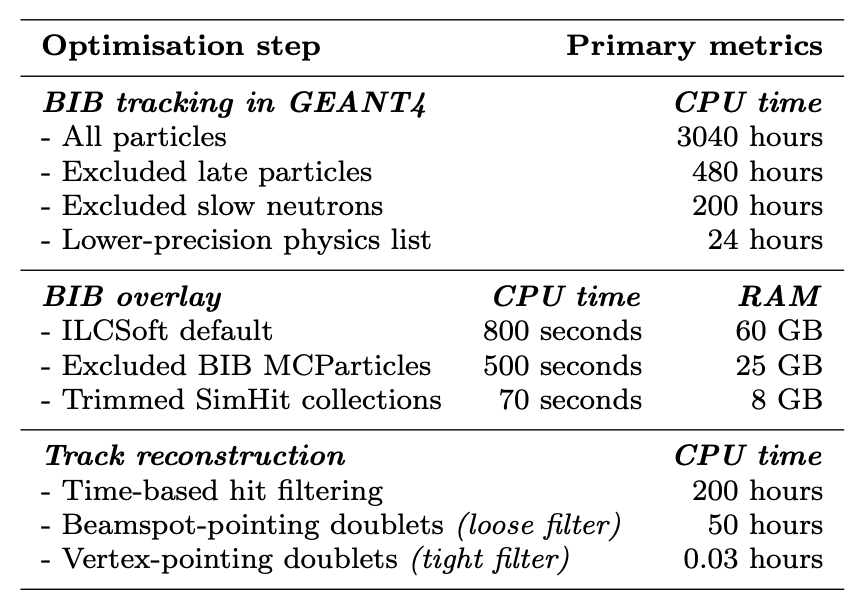
Energy deposits in the calorimeter released by background particles (left) and their energy vs time correlation (middle)
Such irrelevant particles were identifying by looking at the correlation between the kinetic energy of the neutrons entering the detector region (Y axis), and the time of every energy release until they stop (X axis). Since we are only interested in the energy deposits within the 10 ns time window, practically all particles with kinetic energy below 150 MeV (mega electron-volt) arrive later than that, because they are too slow.
Excluding such slow neutrons reduces the simulation time by another factor 3, down to 200 hours. This higher energy threshold allowed to use a less precise physics model than was required by the slower neutrons. It works much faster and ultimately brought the simulation time down to just 24 hours.
If you're interested in more technical details of this study, you can read the full publication:
